New AI 3D generators launch every month. Each one claims to be the best. Marketing screenshots look great, but how do the actual outputs compare when you strip away the branding?
That's what top3d.ai solves. The Arena uses blind community voting and a proven rating system to rank every major AI 3D generator. This article explains the full methodology.
How Blind Voting Works
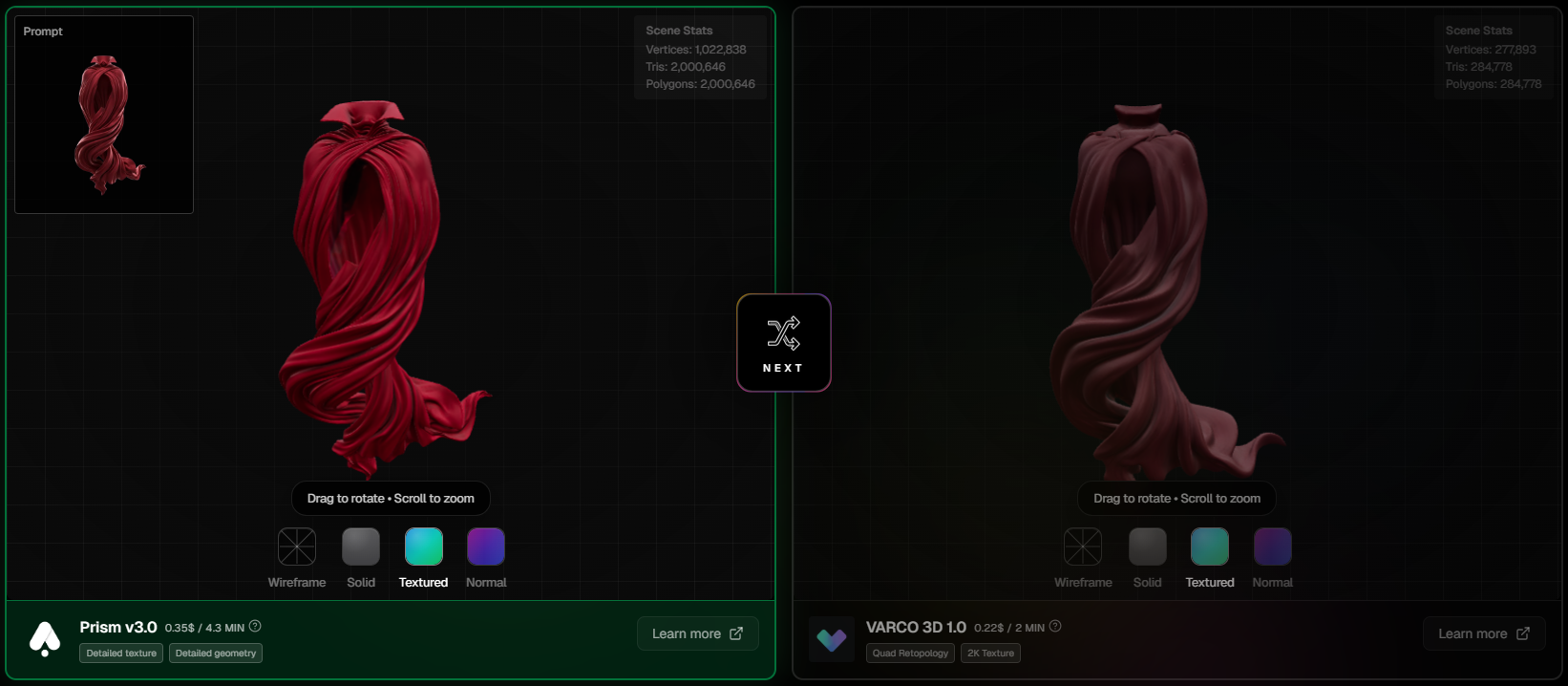
When you enter the Arena, you see two 3D models side by side, both generated from the same text prompt by two different AI tools. You don't know which tool made which model. No logos, no names, no bias.
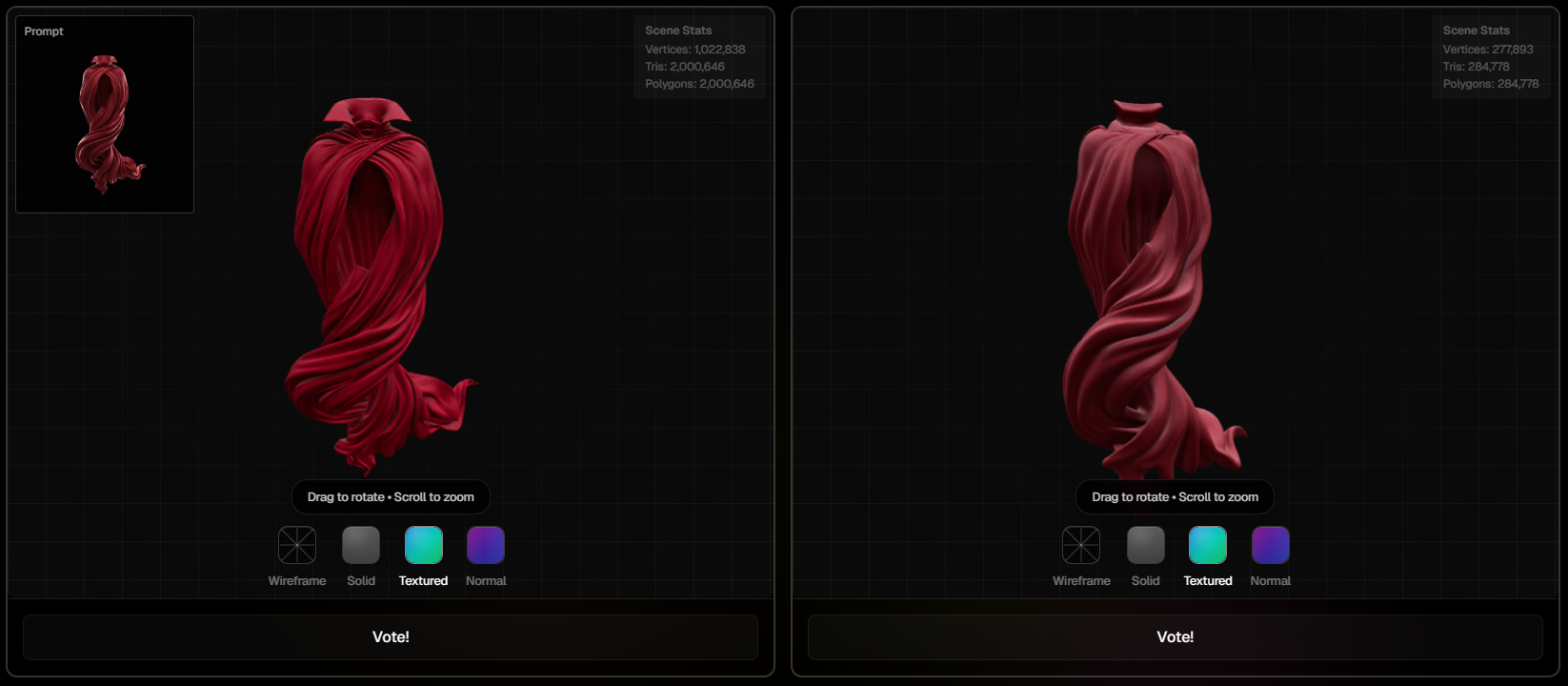
Inspect both models
Vote for the better one
See the reveal
Four Evaluation Modes
The Arena has four modes, each testing a different aspect of 3D generation. Each mode maintains its own separate ELO leaderboard, so a tool that excels at textures might rank differently in geometry.

Textured
The default mode. Full PBR materials and textures applied. You're judging overall visual quality: do the textures look clean, are materials realistic?
Geometry
Textures stripped away, solid grey view. You're judging the mesh itself: is the topology clean, are proportions correct, is the surface smooth where it should be?
Low Poly
Low-polygon outputs optimized for game engines. You're judging retopology quality: is the poly count efficient, does the silhouette hold up, is it game-ready?
Segmentation
AI-detected parts highlighted in different colors. You're judging how well the tool understands object structure. Are the parts correctly separated for rigging and animation?
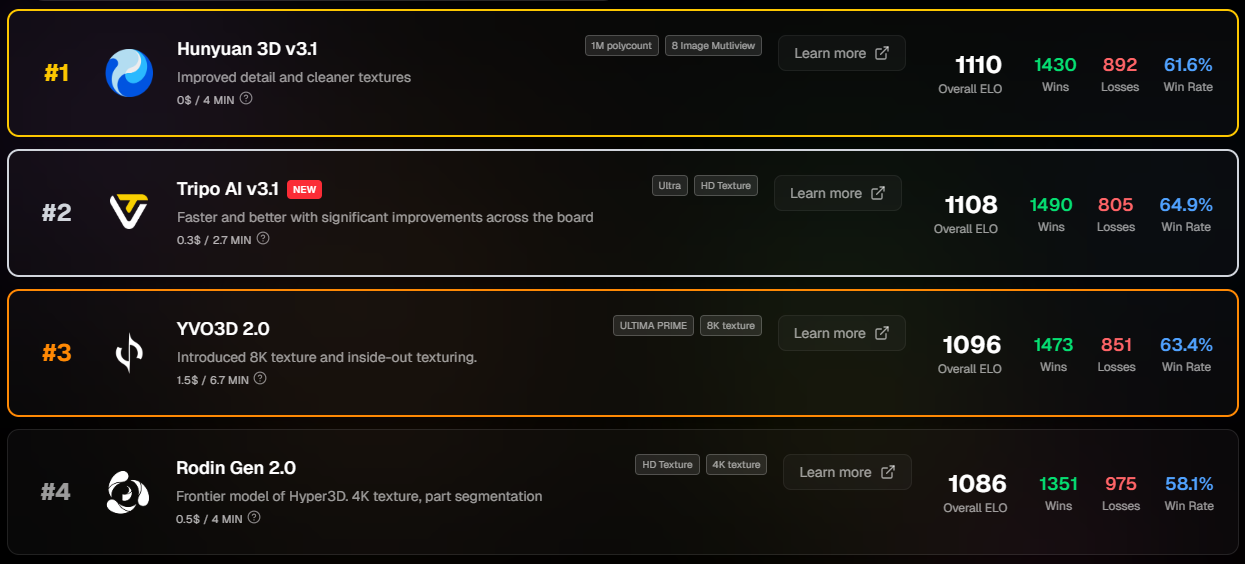
The ELO Rating System
We use the ELO rating system, the same method used in chess to rank players. Simple, proven, and self-correcting.
How it works
- Every tool starts at 1000 ELO
- When two tools face each other, the system calculates the expected outcome based on their current ratings
- Beating a stronger tool earns more points than beating a weaker one
- Upsets matter more. When a lower-rated tool wins against a top-ranked one, the rating shift is significant
- Over time, ratings converge on true quality. Marketing spend can't buy ELO points
Rating Volatility (K-Factor)
New tools need to find their level quickly. Established tools should have stable ratings. We handle this with a sliding K-factor that controls how much each vote can move a rating:
| Tool's Total Votes | K-Factor | Behavior |
|---|---|---|
| Less than 10 | 32 | High volatility, finds level fast |
| 10–29 | 24 | Establishing, still adjusting |
| 30–99 | 16 | Established, moderate changes |
| 100+ | 8 | Well-established, small precise shifts |
This means a new tool can climb (or drop) rapidly in its first dozen matchups, while a tool with 500+ votes will only shift by a few points per vote.
How Matchups Are Selected
Fairness is critical. Our matchmaking algorithm ensures every tool gets a fair shot:
- Random prompt selection. Each round picks a random text prompt from our test set, so you see a variety of objects
- Weighted tool selection. Tools with fewer votes get prioritized, ensuring new additions are tested quickly
- No self-matching. A tool never faces itself
What This Means for You
Choosing a tool?
The ELO leaderboard reflects real output quality judged by the community, not marketing claims. Higher ELO = consistently wins blind comparisons.
Building a tool?
Your ranking is based on blind comparisons. Improvements to your model will be reflected in the data. No need to spend on marketing, just ship better quality.
Doing research?
Our dataset of 90K+ blind votes across 21 generators is one of the largest independent benchmarks for AI 3D generation.
Try It Yourself
Every vote helps the community make better decisions. A single round takes about 30 seconds.


